- Mail:
- info@digital4pro.com

Software: Architettura Kappa

Career: Become a certainty
29 Marzo 2021
Carriera: Diventa unico!
31 Marzo 2021
L’architettura Kappa è un’architettura software utilizzata per l’elaborazione dei dati in streaming. Il principale obiettivo dell’architettura Kappa è eseguire sia l’elaborazione in tempo reale che quella in batch, soprattutto finalizzata all’analisi, con un unico stack tecnologico.
L’architettura Kappa si basa su un’architettura di streaming in cui una serie di dati in entrata viene prima memorizzata in un motore di messaggistica come Apache Kafka®. Da lì, un motore di elaborazione in streaming leggerà i dati e li trasformerà in un formato analizzabile, per poi memorizzarli in un database di analisi che gli utenti finali potranno interrogare.
Un’architettura di streaming è un insieme definito di tecnologie che lavorano insieme per gestire l’elaborazione degli stream, ossia la pratica di agire su una serie di dati al momento della loro creazione.
In molte implementazioni, Apache Kafka® funge da archivio per i dati in streaming e quindi più stream processor possono agire sui dati memorizzati in Kafka per produrre più uscite.
Alcune architetture di streaming includono flussi di lavoro sia per l’elaborazione di flussi che per l’elaborazione in batch, il che comporta altre tecnologie per gestire l’elaborazione in batch su larga scala, oppure l’utilizzo di Kafka come store centrale.
L’architettura Kappa supporta l’analisi in tempo quasi reale quando i dati vengono letti e trasformati immediatamente dopo essere stati inseriti nel motore di messaggistica. Questo rende i dati recenti rapidamente disponibili per le query degli utenti finali.
Tale architettura supporta anche l’analitica storica leggendo i dati di streaming memorizzati dal motore di messaggistica in un secondo momento in modo batch, per creare ulteriori output analizzabili per più tipi di analisi.
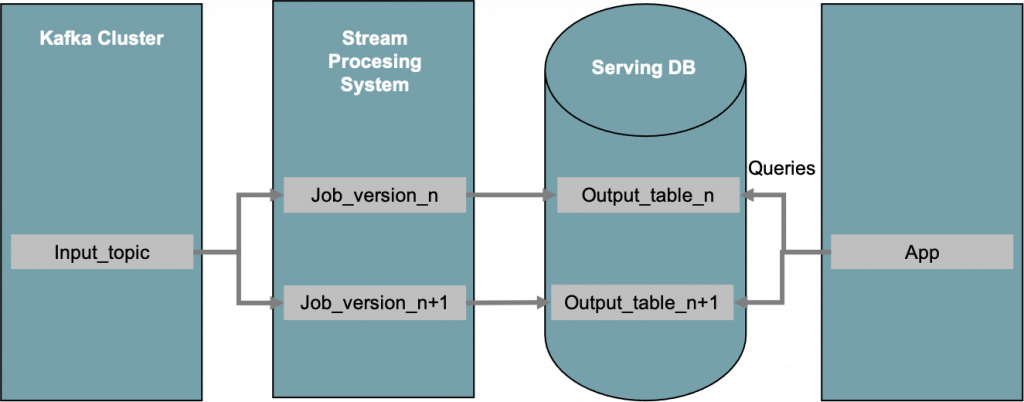
Figura 1 – L’architettura Kappa è tipicamente costruita intorno ad Apache Kafka® congiuntamente ad un motore di elaborazione ad alta velocità.
Differenza tra architettura Lambda e architettura Kappa
L’architettura Kappa è considerata un’alternativa più semplice all’architettura Lambda, in quanto utilizza lo stesso stack tecnologico per gestire sia l’elaborazione dei flussi in tempo reale che l’elaborazione storica in batch.
Entrambe le architetture prevedono l’archiviazione dei dati storici per consentire l’analisi su larga scala.
Entrambe le architetture sono utili anche per affrontare la tolleranza agli errori umani in cui i problemi con il codice di elaborazione possono essere superati aggiornando il codice ed eseguendolo nuovamente sui dati storici.
La differenza principale con l’architettura Kappa è che tutti i dati sono trattati come se fossero un flusso, quindi il motore di elaborazione del flusso agisce come unico motore di trasformazione dei dati.
Entrambe le architetture gestiscono l’analisi storica e in tempo reale in un unico ambiente. Tuttavia, uno dei principali vantaggi dell’architettura Kappa rispetto all’architettura Lambda è che consente di costruire il sistema di streaming e di elaborazione batch su un’unica tecnologia. Ciò significa che è possibile costruire un’applicazione di elaborazione in streaming per gestire i dati in tempo reale e, se vi è la necessità di modificare l’output, si aggiorna il codice e poi lo esegue di nuovo sui dati nel motore di messaggistica in modo batch. Non esiste una tecnologia separata per gestire l’elaborazione in batch, come invece suggerito dall’architettura Lambda.
Con un motore di elaborazione del flusso sufficientemente veloce, potrebbe non essere necessaria una tecnologia separata ottimizzata per l’elaborazione in batch. Supponendo che i dati in Kafka siano opportunamente suddivisi in canali separati, è sufficiente leggere i dati di streaming memorizzati in parallelo e trasformare i dati come se provenissero da una sorgente di streaming. Per alcuni ambienti, è possibile creare potenzialmente l’output analizzabile su richiesta così, quando viene inviata una nuova query da un utente, i dati possono essere trasformati ad hoc per rispondere in modo ottimale a tale query. Anche in questo caso, ciò richiede un motore di elaborazione ad alta velocità per consentire una bassa latenza nell’elaborazione.
Mentre l’architettura Lambda non specifica le tecnologie che devono essere utilizzate, il componente di elaborazione in batch è spesso realizzato su una piattaforma dati su larga scala come Apache Hadoop®.
L’Hadoop Distributed File System (HDFS) può memorizzare i dati grezzi che possono poi essere trasformati tramite gli strumenti Hadoop in un formato analizzabile.
Mentre Hadoop viene utilizzato per il componente di elaborazione batch del sistema, un motore separato progettato per l’elaborazione di flusso viene utilizzato per il componente di analisi in tempo reale.
Un vantaggio dell’architettura Lambda è inoltre che set di dati molto grandi, anche dell’ordine dei petabyte, possono essere memorizzati ed elaborati in Apache Hadoop® in modo più efficiente per l’analisi storica su larga scala.



{kind=link}
{kind=link}
{kind=link}