- Mail:
- info@digital4pro.com

Architettura Lambda

Le dimensioni dell’innovazione
24 Febbraio 2021
Carriera: Sii te stesso!
3 Marzo 2021
L’architettura Lambda è un modello di implementazione per l’elaborazione dei dati utilizzata per combinare una tradizionale pipeline batch con una pipeline real-time stream per l’accesso ai dati.
Si tratta di un modello di architettura comune nei kit di sviluppo software, poiché le organizzazioni sono sempre più orientate ai dati e agli eventi di fronte a volumi massicci di dati generati rapidamente: i cosiddetti big data.
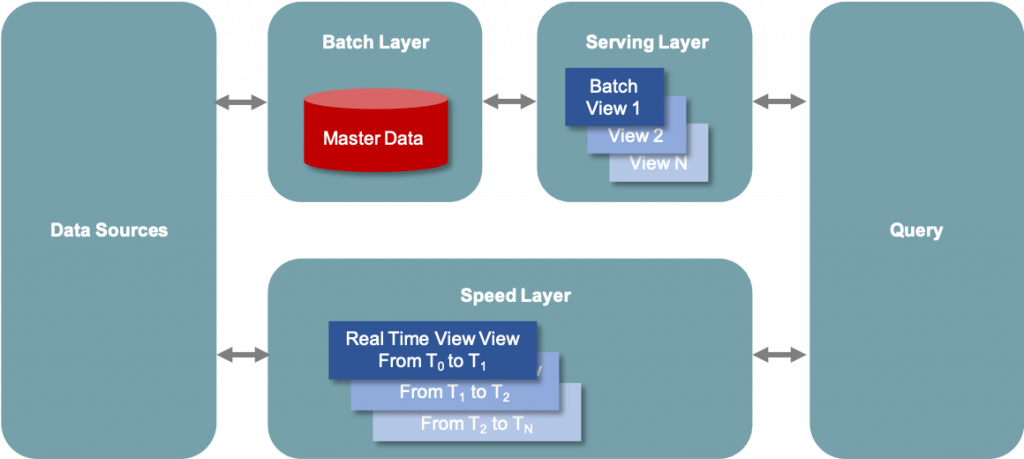
Figura 1 – L’architettura Lambda contiene sia una tradizionale pipeline di dati in batch, sia una pipeline di streaming veloce per i dati in tempo reale, oltre a un livello di servizio per rispondere alle richieste.
I componenti dell’architettura Lambda
I principali componenti dell’architettura Lambda, rappresentati in Figura 1, sono di seguito descritti.
1 Data Sources
I dati possono essere ottenuti da una varietà di fonti, che possono poi essere incluse nell’Architettura Lambda per l’analisi. Questo componente è spesso una fonte di streaming come Apache Kafka, che non è la fonte di dati originale di per sé, ma è un archivio intermedio che può contenere dati al fine di servire sia il Batch Layer che lo Speed Layer dell’architettura Lambda. I dati sono consegnati simultaneamente sia al Batch Layer che allo Speed Layer per consentire un’indicizzazione parallela.
2 Batch Layer
Questo componente salva tutti i dati che entrano nel sistema come viste batch in preparazione per l’indicizzazione. I dati in ingresso vengono salvati in un modello che assomiglia ad una serie di modifiche/aggiornamenti che sono stati fatti ad un sistema di registrazione, simile all’output di un sistema di Change Data Capture (CDC). Spesso si tratta semplicemente di un file in formato Comma-Separated Values (CSV). I dati sono trattati come immutabili per garantire una registrazione storica affidabile di tutti i dati in entrata. Viene spesso utilizzata una tecnologia come Apache Hadoop per il Data Ingestion e per la memorizzazione dei dati.
3 Serving Layer
Questo strato indicizza in modo incrementale le ultime viste batch per renderlo interrogabile dagli utenti finali. Questo strato può anche reindicizzare tutti i dati per correggere un bug di codifica o per creare diversi indici per i diversi casi d’uso. Il requisito chiave del livello di servizio è che l’elaborazione sia fatta in modo estremamente parallelizzato per ridurre al minimo il tempo di indicizzazione del set di dati. Mentre viene eseguito un’attività di indicizzazione, i dati appena arrivati saranno messi in coda per l’indicizzazione nel prossimo Indexing Job.
4 Speed Layer
Questo livello completa il livello di servizio appena descritto indicizzando i dati aggiunti più di recente e non ancora completamente indicizzati dal livello di servizio medesimo. tale attività include i dati che il livello di servizio sta attualmente indicizzando, così come i nuovi dati che sono arrivati dopo l’inizio del lavoro di indicizzazione corrente.
Poiché, a causa del tempo necessario per eseguire il lavoro di indicizzazione in batch, c’è un ritardo tra il momento in cui i dati più recenti sono stati aggiunti al sistema e il momento in cui i dati più recenti sono disponibili per l’interrogazione, spetta allo Speed Layer indicizzare i dati più recenti per ridurre questo divario.
Questo livello tipicamente sfrutta il software di elaborazione dei flussi per indicizzare i dati in entrata in tempo quasi reale riducendo al minimo la latenza dell’ottenimento dei dati disponibili per l’interrogazione.
Quando l’architettura Lambda è stata introdotta per la prima volta, Apache Storm era un motore di elaborazione dei flussi leader utilizzato nelle implementazioni, ma altre tecnologie sono da allora emerse come candidati per questo componente (Hazelcast Jet, Apache Flink, e Apache Spark Streaming).
5 Query
Domanda. Questo componente è responsabile dell’invio delle query dell’utente finale sia al Serving Layer che allo Speed Layer oltre che del consolidamento dei risultati. Questo fornisce agli utenti finali una query completa su tutti i dati, inclusi i dati aggiunti più di recente, per fornire un sistema di analisi quasi in tempo reale.
Come funziona l’architettura Lambda
Il Batch Layer ed il Serving Layer continuano ad indicizzare i dati in entrata in batch. Poiché l’indicizzazione dei batch richiede tempo, lo Speed Layer completa il Batch Layer ed il Serving Layer indicizzando tutti i nuovi dati non indicizzati in tempo quasi reale. In questo modo si ottiene una visione ampia e coerente dei dati nel Batch Layer e nel Serving Layer che possono essere ricreati in qualsiasi momento, insieme ad un indice più piccolo che contiene i dati più recenti.

Figura 2 – I dati sono indicizzati simultaneamente sia dallo strato di servizio che dallo strato di velocità.
Una volta completato un lavoro di indicizzazione in batch, i nuovi dati indicizzati in batch sono disponibili per l’interrogazione, quindi la copia dello Speed Layer degli stessi dati non è più necessaria e viene cancellata dallo strato di velocità. Il livello di servizio inizia quindi a indicizzare gli ultimi dati del sistema che non erano ancora stati indicizzati da questo livello, che è già stato indicizzato dal livello di velocità ed è quindi disponibile per l’interrogazione allo Speed Layer.
Questo passaggio continuo tra lo Speed Layer e il Serving Layer garantisce che tutti i dati siano pronti per l’interrogazione e che la latenza per la disponibilità dei dati sia bassa.
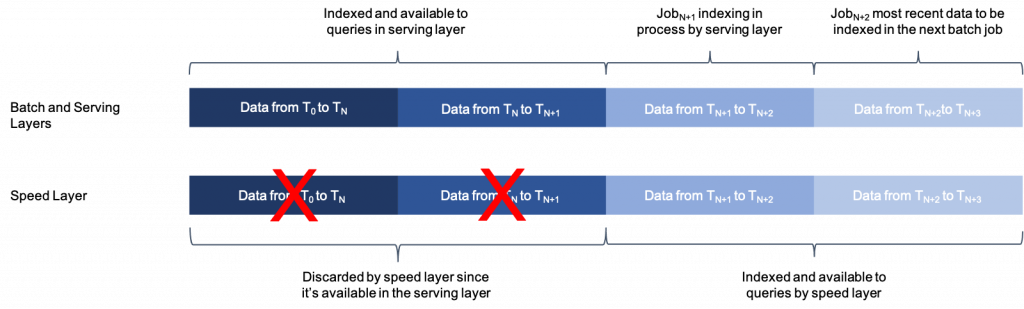
Figura 3 – Quando lo strato di servizio completa un lavoro, si sposta al lotto successivo e lo strato di velocità scarta la sua copia dei dati che lo strato di servizio ha appena indicizzato.
I vantaggi dell’architettura Lambda
L’architettura Lambda cerca di bilanciare le problematiche sulla latenza, la coerenza dei dati, la scalabilità, la tolleranza ai guasti e la tolleranza agli errori umani. Esaminiamo nel seguito ciascuno di questi elementi.
1 Latenza
I dati grezzi sono indicizzati nel Serving Layer in modo che gli utenti finali possano interrogare e analizzare tutti i dati storici. Poiché l’indicizzazione dei batch richiede un po’ di tempo, tende ad esserci una finestra temporale relativamente ampia di dati che non è temporaneamente disponibile per l’analisi da parte degli utenti finali. Lo Speed Layer utilizza tecnologie di elaborazione dei flussi per indicizzare immediatamente i dati recenti che attualmente non sono interrogabili nel Batch Layer e nel Serving Layer, restringendo così la finestra temporale dei dati non analizzabili. Questo aiuta a ridurre la latenza, cioè il tempo di attesa per la messa a disposizione dei dati per l’analisi, che è insita nel Batch Layer e nel Serving Layer.
2 Consistenza dei dati
Un’idea chiave dell’architettura Lambda è che elimina il rischio di incoerenza dei dati cui spesso si assiste nei sistemi distribuiti. In un database distribuito in cui i dati potrebbero non essere consegnati a tutte le repliche a causa di guasti del nodo o della rete, c’è la possibilità di dati incoerenti. In altre parole, una copia dei dati potrebbe riflettere il valore aggiornato, ma un’altra copia potrebbe avere ancora il valore precedente.
Nell’architettura Lambda, poiché i dati vengono elaborati in modo sequenziale e non in parallelo con le sovrapposizioni, come può essere il caso per le operazioni su un database distribuito, il processo di indicizzazione può garantire che i dati riflettano lo stato più recente sia nel Batch Layer che nello Speed Layer.
3 Scalabilità
L’architettura Lambda non specifica le tecnologie da utilizzare, ma si basa su tecnologie distribuite e scalabili che possono essere espanse semplicemente aggiungendo altri nodi. Questo può essere fatto alla fonte dei dati, nel Batch Layer, nel Serving Layer e nello Speed Layer. Questo consente di utilizzare l’architettura Lambda indipendentemente dalla quantità di dati da elaborare.
4 Tolleranza ai guasti
L’architettura Lambda è basata su sistemi distribuiti che supportano la tolleranza ai guasti quindi, se dovesse verificarsi un guasto hardware, sono disponibili altri nodi per continuare l’operatività.
Inoltre, poiché tutti i dati sono memorizzati nel Batch Layer, eventuali guasti durante l’indicizzazione sia nel Serving Layer che nello Speed Layer possono essere superati semplicemente ripetendo il lavoro di indicizzazione nel Batch Layer e nel Serving Layer, e lasciando che lo Speed Layer continui a indicizzare i dati più recenti.
5 Tolleranza agli errori umani
Poiché i dati grezzi vengono salvati per l’indicizzazione, essi fungono da sistema di registrazione per i dati analizzabili e tutti gli indici possono essere ricreati da questo set di dati. Ciò significa che, se ci sono dei bug nel codice di indicizzazione o delle omissioni, il codice può essere aggiornato e poi rieseguito per reindicizzare tutti i dati.
Gli svantaggi dell’architettura Lambda
L’architettura Lambda è spesso criticata come eccessivamente complessa. Ogni pipeline richiede una propria base di codice, e le basi di codice devono essere mantenute in sincronia per garantire risultati coerenti e precisi quando le query toccano entrambe le pipeline.
Differenza tra architettura Lambda e architettura Kappa
L’architettura Kappa è simile all’architettura Lambda a meno di un insieme di tecnologie per la pipeline batch.
Tutti i dati vengono semplicemente indirizzati attraverso una pipeline per l’elaborazione dei flussi. Tutti i dati sono memorizzati in un bus di messaggistica (come Apache Kafka) e, quando è richiesta la reindicizzazione, i dati vengono riletti da quella fonte.
Si tratta di un approccio semplificato in quanto richiede un solo codice base ma, nelle organizzazioni con dati storici dei sistemi batch tradizionali, si tratta di decidere se il passaggio a un ambiente di solo streaming compensa la spesa per il cambiamento delle piattaforme.
Inoltre, i bus di messaggi non sono così efficienti per finestre di tempo estremamente ampie di dati rispetto alle piattaforme di dati che sono convenienti in termini di costi per set di dati più grandi. Ciò significa che non è sempre possibile memorizzare l’intera cronologia dei dati in un’architettura Kappa. Tuttavia, le innovazioni tecnologiche stanno abbattendo questa limitazione in modo che set di dati molto più grandi possano essere memorizzati nei bus di messaggi come flussi on-demand, per consentire all’architettura Kappa di essere adottata in modo più universale.
Alcune tecnologie di elaborazione degli stream supportano anche i paradigmi di elaborazione in batch, in modo da poter utilizzare i repository di dati su larga scala come fonte accanto a un repository di streaming. In questo modo è possibile elaborare set di dati estremamente grandi in modo economico e allo stesso tempo ottenere la semplicità di utilizzare un solo motore di elaborazione.



{kind=link}
{kind=link}
{kind=link}