- Mail:
- info@digital4pro.com

Big Data as a Service

The Spiral of Silence by Noelle-Neumann
7 Settembre 2020
Big Data as a Service
8 Settembre 2020
Given the inherent difficulty in extracting value from Big Data¹, it is not surprising that most companies can identify current or future challenges or opportunities in Big Data.
The cost-effectiveness of storage, the collection of oblique data as well as the availability of third-party data have exceeded the capabilities of traditional data warehouses and processing solutions.
Companies that study Big Data regularly recognize that they do not have the ability to process and store them properly. This is manifested in the inability to make the best use of existing big data sets or to expand their current data strategy with additional data.
Today, as a result of the growing trend in demand for Big Data processing, companies can turn to Big Data as a Service (BDaaS) solutions to bridge the storage and processing gap. In the absence of a single classification regarding BDaaS, we ask ourselves what the different types of BDaaS are available.
Three levels of cloud computing as a service
Big data as a service is sometimes mistakenly equated to Hadoop² as a service and cloud computing³. Public⁴ and hybrid⁵ cloud offerings are developing very rapidly, which is natural due to the sizeable existing market and the ability to take advantage of available technologies and infrastructure.
Although Hadoop is currently the most important distributed storage and processing environment, we can divide the offer of Big Data as a Service on the market into three categories:
- Infrastructure as a service (IaaS) which includes virtual machines, networks, storage or servers. This is the most basic configuration and includes everything (be it real or virtual) what is expected from a data center.
- Platform as a Service (PaaS) which includes software commonly used as a web and database server or Hadoop and its ecosystem.
- Software as a service (SaaS) which sees generic services, but more aimed at the user such as web email, content or customer relationship management systems. Finally, in addition to SaaS there are usually domain or business specific applications.
Four models of Big Data as a Service
A Hadoop ecosystem or alternative distributed platform-level processing and storage technology naturally forms the core of a BDaaS.
Consequently, any BDaaS solution includes the PaaS level and potentially SaaS and / or IaaS. This brings us to four possible combinations of BDaaS:
- PaaS only: focusing on Hadoop;
- IaaS and PaaS: attention to Hadoop and infrastructure optimized for performance;
- PaaS and SaaS: attention to Hadoop and functionality for productivity and interchangeable infrastructure;
- IaaS and PaaS and SaaS: attention to complete vertical integration in terms of functionality and performance.
Considering the three levels of cloud computing as a service just seen, we can distinguish four models of Big Data as a Service.
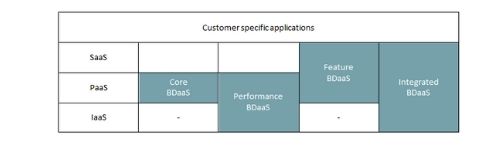
1. Core BDaas
The BDaaS core implements the minimal platform, e.g. Hadoop with YARN⁶ and HDFS ⁷ and some popular services like Hive⁸.
Amazon Web Service’s Elastic MapReduce⁹ (EMR) is the most important and representative BDaaS core of this model. EMR is one of the countless services in Amazon’s offer and EMR integrates well with many other services such as the NoSQL¹º DynamoDB¹¹ or S3¹² store.
Users can combine them to create anything from data pipelines to complete corporate infrastructure around the EMR service. However, Amazon’s strength and the modularity of its services means that the main offer of BDaaS is destined to remain generic to interact with the rest of the services.
2. Performance BDaaS
A vertical integration path for BDaaS down to include an optimized infrastructure. This allows you to eliminate some virtualization overheads and in particular to create servers and hardware networks capable of meeting the performance needs of Hadoop.
An example of BDaaS performance is SAP Altiscale¹³. Organizations can outsource their infrastructure and platform needs in addition to managing Hadoop in Altiscale. Companies can therefore focus on the operation of Hadoop and on the stack from SaaS upwards.
A package pricing approach based on storage and processing usage is intended to optimize the balance between performance and cost optimization, thus providing predictable fixed costs.
3. Feature BDaaS
The third integration path for BDaaS is upward to include functionality beyond the common offerings of the Hadoop ecosystem.
Qubole¹⁴, a startup founded by Ashish Thusoo and Joydeep Sen Sarma who lead Facebook’s data infrastructure team, has adopted this approach. BDaaS functionality focuses on productivity and abstraction to allow users to quickly get started with Big Data. Their offering includes web and programming interfaces, as well as database adapters that push technologies like Hadoop into the background. Their offer reaches the SaaS level. Hadoop clusters are started, resized and even stopped transparently when required by the load.
Like the BDaaS core, the feature-based approach uses IaaS to provide processing and storage, albeit with a significant difference. Independence from a cloud service provider allows a BDaaS function to view the calculation and storage as a fully scalable and, above all, exchangeable product such as electricity or water. Qubole, for example, already supports Amazon and Google’s IaaS. The calculation and storage from IaaS can be purchased a little at a time and therefore ideal for highly variable, unpredictable or exploratory workloads.
4. Integrated BDaaS
Finally, another option is a fully vertically integrated BDaaS that combines the performance and benefits of the functions of the two previous BDaaS.
This is an attractive approach since it could lead to a productive BDaaS that supports users and business experts and offers maximum performance.
Conclusions
As Big Data is maturing, business and service models are emerging. We can see the advantages and differences between Big Data models as a service. The BDaaS core has been around for some years and has been used by many companies primarily as part of a larger architecture or for irregular workloads. It has established itself as a model to support the broader service architecture of the provider.
BDaaS functionality and performance attack the segment with very different value propositions and there are good reasons to continue attracting both customers. Both will face some features of the other in the long run. For example, the BDaaS function must demonstrate that it is competitive in terms of performance.
The performance that BDaaS will face are the needs of companies less and less willing to face the complex challenges of building their own data architecture and its SaaS level and who want to focus more and more on their specific value-added domain processes.
¹ https://en.wikipedia.org/wiki/Big_data
² Hadoop is an open source software, stable and scalable, designed for distributed computing, that is, for processing natively operating on autonomous machines, but federated together to add up the calculation capabilities of the individual computers. Hadoop was born to be used on low cost machines which, thanks to their federation, can offer reliability typical of custom systems. A further strength of the solution is the potential reduction of the license costs offered by the open source distribution. https://hadoop.apache.org
³ https://en.wikipedia.org/wiki/Cloud_computing
⁴ https://en.wikipedia.org/wiki/Cloud_computing#Public_cloud
⁵ https://en.wikipedia.org/wiki/Cloud_computing#Hybrid_cloud
⁶ https://classic.yarnpkg.com/en/
⁷ https://en.wikipedia.org/wiki/Apache_Hadoop#HDFS
¹¹ https://aws.amazon.com/it/dynamodb/
¹² https://aws.amazon.com/it/s3/
¹³ https://portal.altiscale.com/login
Bibliografy:
- Big Data Analytics: Il manuale del data scientist, Alessandro Rezzani



{kind=link}
{kind=link}
{kind=link}