- Mail:
- info@digital4pro.com

Big Data as a Service

Big Data as a Service
8 Settembre 2020
Dare to make a mistake!
9 Settembre 2020
Data l’intrinseca difficoltà nell’estrazione di valore dai Big Data¹, non sorprende che la maggior parte delle aziende possano identificare nei Big Data sfide o opportunità attuali o future.
L’economicità dello storage, la raccolta di dati obiqui oltre alla disponibilità di dati di terze parti hanno superato le capacità dei tradizionali data warehouse e delle soluzioni di elaborazione.
Le aziende che studiano i Big Data riconoscono regolarmente di non avere la capacità di elaborarli e archiviarli in modo adeguato. Ciò si manifesta nell’incapacità di utilizzare al meglio i set di big data esistenti o di espandere la loro attuale strategia di dati con dati aggiuntivi.
Oggi, in conseguenza della tendenza di crescita nella domanda di elaborazione dei Big Data, le aziende possono rivolgersi alle soluzioni Big Data as a Service (BDaaS) per colmare il divario di archiviazione ed elaborazione. In mancanza di una classificazione univoca in merito ai BDaaS, ci chiediamo quali siano i diversi tipi di BDaaS disponibili.
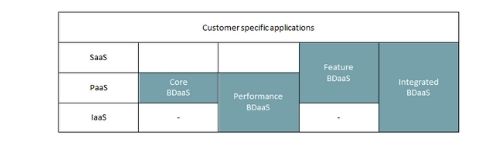
Tre livelli di cloud computing come servizio
I Big Data come servizio sono a volte erroneamente equiparati a Hadoop² come servizio e al cloud computing³. Le offerte di cloud pubblico⁴ e ibrido⁵ si stanno sviluppando molto rapidamente, il che è naturale a causa del considerevole mercato esistente e della capacità di sfruttare le tecnologie e le infrastrutture disponibili.
Sebbene Hadoop sia attualmente l’ambiente di archiviazione ed elaborazione distribuito più importante, possiamo articolare in tre categorie l’offerta di Big Data as a Service sul mercato:
- Infrastruttura come servizio (Infrastructure as a service, IaaS) che comprende macchine virtuali, reti, storage o server. Si tratta della configurazione più elementare ed include tutto (sia esso reale o virtuale) ciò che ci si aspetta da un data center.
- Piattaforma come servizio (Platform as a Service, PaaS) che include il software comunemente utilizzato come server Web e database o Hadoop e il suo ecosistema.
- Software come servizio (Software as a Service, SaaS) che vede servizi generici, ma più rivolti all’utente come e-mail web, contenuti o sistemi di gestione delle relazioni con i clienti. Infine, oltre a SaaS ci sono solitamente applicazioni specifiche di dominio o aziendali.
Quattro modelli di Big Data as a Service
Un ecosistema Hadoop o una tecnologia di elaborazione e archiviazione distribuita alternativa a livello di piattaforma costituisce naturalmente il nucleo di un BDaaS.
Di conseguenza, qualsiasi soluzione BDaaS include il livello PaaS e potenzialmente SaaS e/o IaaS. Questo ci porta a quattro possibili combinazioni di BDaaS:
- Solo PaaS: concentrandosi su Hadoop;
- IaaS e PaaS: attenzione a Hadoop e infrastruttura ottimizzata per le prestazioni;
- PaaS e SaaS: attenzione a Hadoop e funzionalità per la produttività e l’infrastruttura intercambiabile;
- IaaS e PaaS e SaaS: attenzione alla completa integrazione verticale per funzionalità e prestazioni.
Considerati i tre livelli di cloud computing come servizio appena visti, possiamo distinguere quattro modelli di Big Data as a Service.
1. Core BDaas
Il core BDaaS implementa la piattaforma minima, ad esempio Hadoop con YARN⁶ e HDFS ⁷ e alcuni servizi popolari come Hive⁸.
Elastic MapReduce⁹ (EMR) di Amazon Web Service è il BDaaS core più importante e rappresentativo di questo modello. EMR è uno degli innumerevoli servizi nell’offerta di Amazon ed EMR si integra bene con molti altri servizi come lo store NoSQL¹º DynamoDB¹¹ o S3¹².
Gli utenti possono combinarli per creare qualsiasi cosa, da pipeline di dati a infrastrutture aziendali complete intorno al servizio EMR. Tuttavia, la forza di Amazon e la componibilità dei suoi servizi, comporta che l’offerta principale di BDaaS sia destinata a rimanere generica per interagire con il resto dei servizi.
2. Performance BDaaS
Un percorso di integrazione verticale per BDaaS verso il basso per includere un’infrastruttura ottimizzata. Ciò consente di eliminare alcune spese generali di virtualizzazione e di creare in particolare server e reti hardware in grado di soddisfare le esigenze prestazionali di Hadoop.
Un esempio di performance BDaaS è Altiscale¹³ di SAP. Le organizzazioni possono esternalizzare le loro esigenze di infrastruttura e piattaforma oltre alla gestione di Hadoop ad Altiscale. Le aziende possono quindi concentrarsi sul funzionamento di Hadoop e sullo stack da SaaS verso l’alto.
Un approccio basato sui prezzi dei pacchetti in funzione dell’archiviazione e dell’utilizzo dell’elaborazione ha lo scopo di ottimizzare il bilanciamento tra prestazioni e ottimizzazione dei costi, fornendo così costi fissi prevedibili.
3. Feature BDaaS
Il terzo percorso di integrazione per BDaaS è verso l’alto per includere funzionalità al di là delle comuni offerte dell’ecosistema Hadoop.
Qubole¹⁴, una startup fondata da Ashish Thusoo e Joydeep Sen Sarma che guidano il team di infrastrutture dati di Facebook, ha adottato questo approccio. La funzionalità BDaaS è incentrata sulla produttività e l’astrazione per consentire agli utenti di iniziare rapidamente a lavorare con i Big Data. La loro offerta comprende interfacce Web e di programmazione, nonché adattatori di database che spingono in background tecnologie come Hadoop. La loro offerta raggiunge il livello SaaS. I cluster Hadoop vengono avviati, ridimensionati e persino arrestati in modo trasparente quando richiesto dal carico.
Analogamente al core BDaaS, l’approccio basato sulle funzionalità utilizza IaaS per fornire elaborazione e archiviazione anche se con una differenza significativa. L’indipendenza da un fornitore di servizi cloud consente a una funzione BDaaS di visualizzare il calcolo e l’archiviazione come un prodotto completamente scalabile e, soprattutto, scambiabile come l’elettricità o l’acqua. Qubole, ad esempio, supporta già Amazon e IaaS di Google. Il calcolo e l’archiviazione da IaaS sono acquistabili un poco alla volta e quindi ideali per carichi di lavoro molto variabili, imprevedibili o esplorativi.
4. Integrated BDaaS
Infine, un’altra opzione è un BDaaS completamente integrato verticalmente che combina le prestazioni e i vantaggi delle funzioni dei due precedenti BDaaS.
Si tratta di un approccio accattivante poiché potrebbe portare ad un BDaaS produttivo e che supporta utenti ed esperti aziendali e offre le massime prestazioni.
Conclusioni
Poiché i Big Data stanno maturando, stanno emergendo modelli di business e di servizio. Possiamo vedere i vantaggi e le differenze tra i modelli di Big Data come servizio. Il core BDaaS è in circolazione da alcuni anni ed è utilizzato da molte aziende soprattutto come parte di un’architettura più ampia o per carichi di lavoro irregolari. Si è affermato come modello a supporto della più ampia architettura di servizi del provider.
La funzionalità e le prestazioni BDaaS attaccano il segmento con proposte di valore molto diverse e ci sono buoni motivi per continuare ad attirare entrambi i clienti. Entrambi dovranno affrontare alcune funzionalità dell’altro nel lungo periodo. Ad esempio, la funzione BDaaS deve dimostrare di essere competitiva a livello di prestazioni.
Le prestazioni che BDaaS affronterà sono le esigenze di aziende sempre meno disposte ad affrontare le complesse sfide della costruzione della propria architettura di dati e del relativo livello SaaS e che desiderano concentrarsi sempre più sui loro processi specifici di dominio a valore aggiunto.
¹ https://en.wikipedia.org/wiki/Big_data
² Hadoop è un software open source, stabile e scalabile, pensato per il calcolo distribuito, ossia per un’elaborazione nativamente operante su macchine autonome, ma federate tra loro per sommare le capacità di calcolo dei singoli computer. Hadoop nasce per essere utilizzato su macchine a basso costo che, grazie alla loro federazione, possono offrire affidabilità tipiche di sistemi custom. Ulteriore punto di forza della soluzione è il potenziale abbattimento dei costi di licenza offerto dalla distribuzione open source. https://hadoop.apache.org
³ https://en.wikipedia.org/wiki/Cloud_computing
⁴ https://en.wikipedia.org/wiki/Cloud_computing#Public_cloud
⁵ https://en.wikipedia.org/wiki/Cloud_computing#Hybrid_cloud
⁶ https://classic.yarnpkg.com/en/
⁷ https://en.wikipedia.org/wiki/Apache_Hadoop#HDFS
¹¹ https://aws.amazon.com/it/dynamodb/
¹² https://aws.amazon.com/it/s3/
¹³ https://portal.altiscale.com/login
Bibliografia:
- Big Data Analytics: Il manuale del data scientist, Alessandro Rezzani



{kind=link}
{kind=link}
{kind=link}